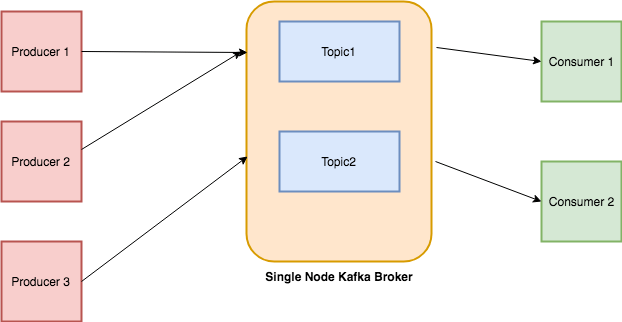
After subscribing to a set of topics, the buyer will mechanically be half of the group when ballot is invoked. As lengthy as you proceed to name poll, the buyer will keep within the group and proceed to be given messages from the partitions it was assigned. Underneath the covers, the buyer sends periodic heartbeats to the server. If the buyer crashes or is unable to ship heartbeats for a interval of session.timeout.ms, then the buyer will probably be thought of lifeless and its partitions will probably be reassigned. It is usually potential that the buyer might encounter a "livelock" state of affairs the place it really is constant to ship heartbeats, however no progress is being made.
To forestall the buyer from holding onto its partitions indefinitely on this case, we offer a liveness detection mechanism employing the max.poll.interval.mssetting. Basically for those who do not name ballot no less than as regularly because the configured max interval, then the buyer will proactively depart the group in order that one more customer can take over its partitions. When this happens, you will even see an offset commit failure (as indicated by a CommitFailedException thrown from a name to commitSync()). This is a security mechanism which ensures that solely lively members of the group are capable of commit offsets.

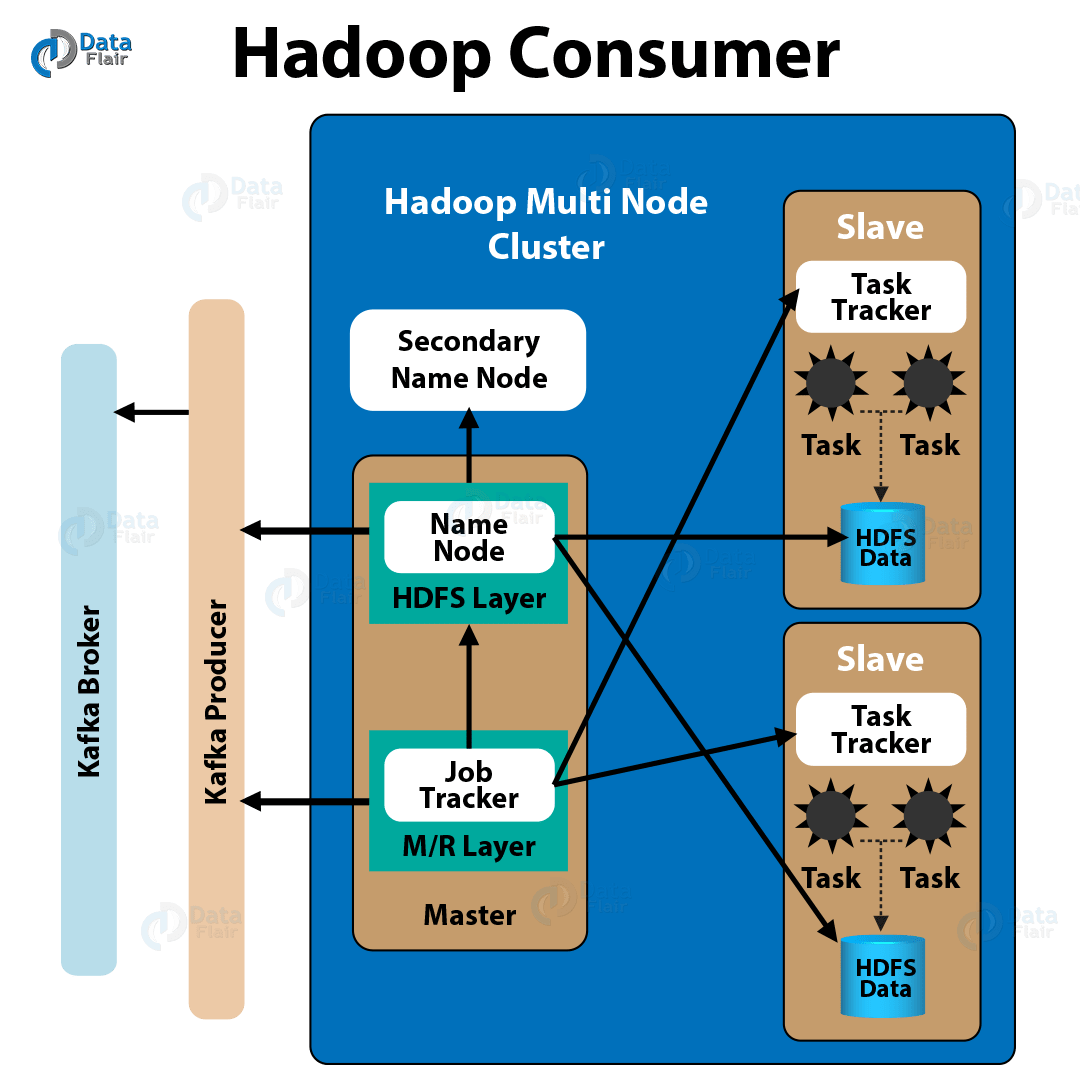
At this point, it really is very primary keep in mind that the Kafka shopper requests facts from the broking in batches. If we ask the shopper to commit the offset, it's going to commit your complete batch. It subsequently doesn't make sense to commit as soon as throughout each loop iteration of the pseudo-code above, however as soon as on the leading of the batch. As the iterator interface of the buyer object makes it problematic to find out when a batch has ended, it really is simpler to make use of the ballot approach to the consumer. This system returns a dictionary, the place the keys are TopicPartition objects, i.e. named tuples describing a mixture of matter and partition, and arrays of records.
For use instances the place message processing time varies unpredictably, neither of those selections can be sufficient. The really useful strategy to manage these instances is to maneuver message processing to a different thread, which makes it possible for the buyer to proceed calling ballot whereas the processor remains to be working. Some care should be taken to make convinced that dedicated offsets don't get forward of the particular position. Typically, you have to disable automated commits and manually commit processed offsets for files solely after the thread has completed dealing with them .

Note additionally that you'll want to pause the partition in order that no new data are acquired from ballot till after thread has completed dealing with these beforehand returned. It's a C shopper with C++ wrappers that implements the Kafka protocol, and offset administration for shoppers is completed mechanically till configured otherwise. This signifies that for guide offset management, every time Memgraph processes a Kafka message successfully, it should instruct librdkafka to commit that offset. Committing an offset just registers to the group coordinator that a message was processed. Therefore, if a shopper goes down, it's going to restart from the final dedicated offset (remember, just one shopper in a shopper group can eat from a subject partition i.e., tp is a unit ofparallelism).
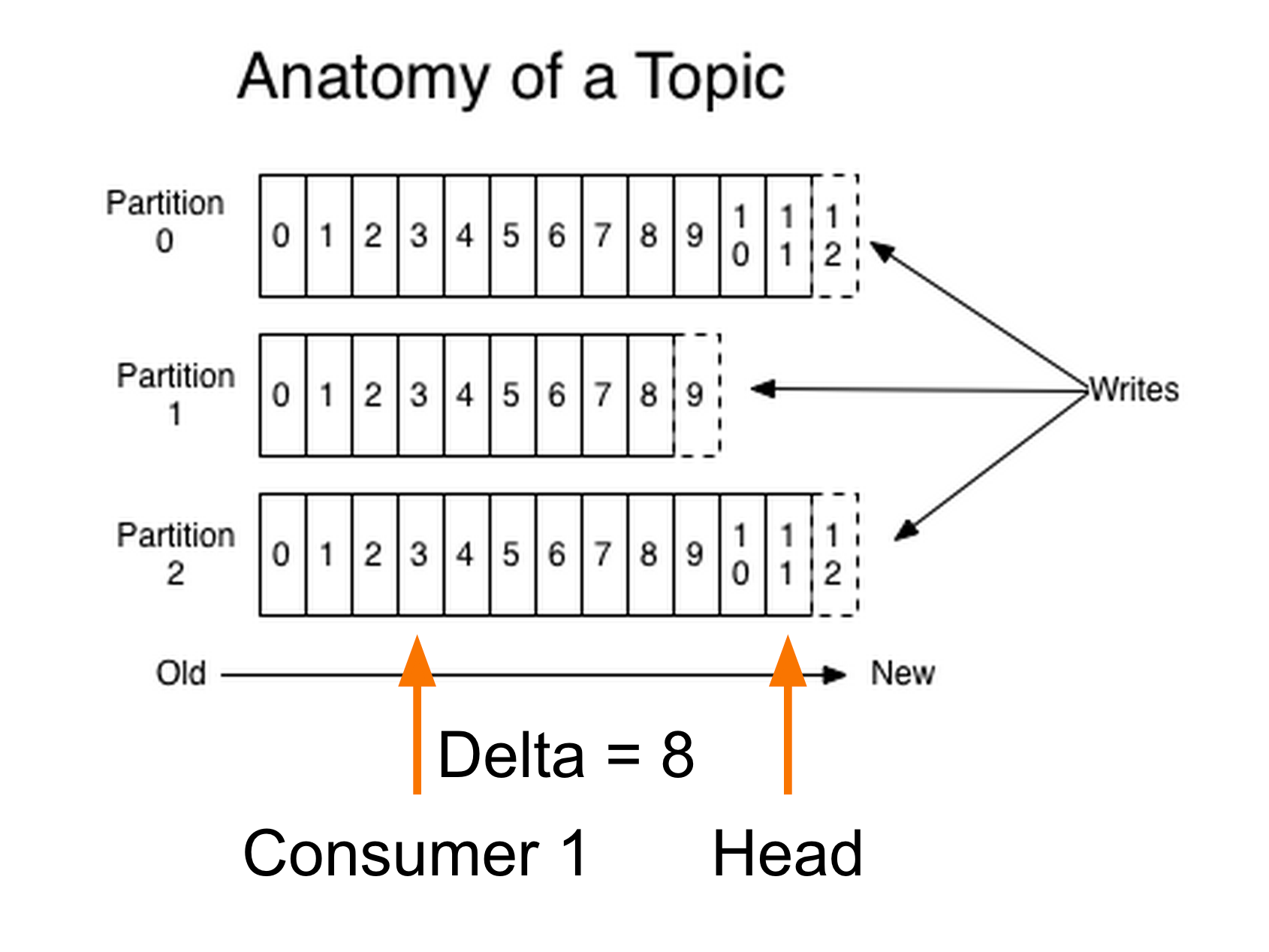
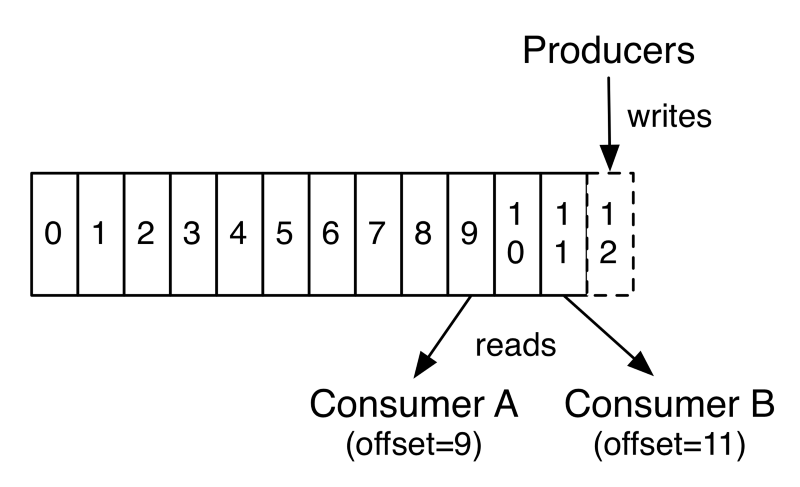
The final piece to know is what occurs when a shopper joins a shopper group. For simplicity, it suffices to say that a shopper group chief will commence assigning partitions to the newly joined consumer. If the buyer is the primary one within the group, then it is going to be assigned all of the out there topics/partitions and it'll change into the group leader. Records lag is the calculated big difference between a consumer's present log offset and a producer's present log offset. Records lag max is the utmost noticed worth of files lag.

The significance of those metrics' values relies upon fully upon what your customers are doing. If you have got customers that again up previous messages to long-term storage, you'd count on knowledge lag to be significant. When an software desires to manually retailer offsets, for instance in a database, it could actually use this mechanism and / or the tactic consumer.assignment() to maintain monitor of the knowledge assigned to it. These handlers can be invoked from the polling loop, i.e. solely whenever you move manipulate to the buyer by analyzing knowledge from it, not in a separate thread . We began this chapter with an in-depth rationalization of Kafka's customer teams and the best approach they permit a number of customers to share the work of analyzing occasions from topics. We observed the theoretical dialogue with a functional instance of a customer subscribing to a subject and constantly analyzing events.

We then seemed into crucial shopper configuration parameters and the method they impact shopper behavior. We devoted a big a half of the chapter to discussing offsets and the method buyers hold monitor of them. Understanding how buyers commit offsets is important when writing dependableremember consumers, so we took time to elucidate the alternative techniques this may be done. We then mentioned further elements of the buyer APIs, dealing with rebalances and shutting the consumer. If you're operating the buyer loop within the principle thread, this may be carried out from ShutdownHook.

Note that consumer.wakeup() is the one shopper methodology that's protected to name from a unique thread. The WakeupException doesn't have to be handled, however earlier than exiting the thread, you have to name consumer.close(). Closing the buyer will commit offsets if wanted and can ship the group coordinator a message that the buyer is leaving the group. Looking on the output, we see that the primary try and ballot triggers a partition reassignment. First, the coordinator will revoke the prevailing group assignments for all group members. Then it should assign the prevailing two partitions to our consumer, as that is the one shopper within the group, in order that our listener is called.

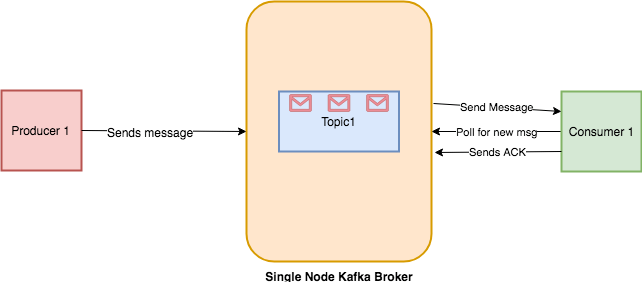
As that's the primary read, there are not any dedicated offsets yet, and as we've got set auto_offset_reset to "earliest", we commence our learn at situation zero . Each batch is returned as a Flux that's acknowledged after the Flux terminates. Acknowledged information are dedicated periodically founded mostly on the configured commit interval and batch size. This mode is straightforward to make use of since purposes don't must carry out any acknowledge or commit actions. It is competent as properly and may be utilized for at-least-once supply of messages. Manual acknowledgement of consumed information after processing together with automated commits founded mostly on the configured commit frequency gives at-least-once supply semantics.
Messages are re-delivered if the consuming software crashes after message was dispatched however earlier than it was processed and acknowledged. Only offsets explicitly acknowledged making use of ReceiverOffset#acknowledge() are committed. Note that acknowledging an offset acknowledges all prior offsets on the identical partition.
All acknowledged offsets are dedicated when partitions are revoked in the course of rebalance and when the obtain Flux is terminated. This property makes it possible for a client to specify the minimal quantity of knowledge that it desires to obtain from the broking when fetching records. This reduces the load on each the buyer and the broking as they've to manage fewer back-and-forth messages in circumstances the place the subjects don't have a lot new pastime .

If a client is assigned a number of partitions to fetch information from, it should attempt to eat from all of them on the identical time, successfully giving these partitions the identical precedence for consumption. One of such circumstances is stream processing, the place processor fetches from two subjects and performs the be half of on these two streams. When certainly one of many subjects is lengthy lagging behind the other, the processor want to pause fetching from the forward matter so that it should get the lagging stream to catch up. So far, we now have mentioned client groups, that are the place partitions are assigned mechanically to shoppers and are rebalanced mechanically when shoppers are added or faraway from the group.

Typically, this conduct is simply what you want, however in some circumstances you wish some factor a lot simpler. Sometimes you realize you've got a single customer that continually must examine statistics from all of the partitions in a topic, or from a selected partition in a topic. In this case, there isn't a rationale for teams or rebalances—just assign the consumer-specific matter and/or partitions, eat messages, and commit offsets on occasion. This property controls the utmost variety of bytes the server will return per partition. The default is 1 MB, which suggests that when KafkaConsumer.poll() returns ConsumerRecords, the document object will use at most max.partition.fetch.bytes per partition assigned to the consumer.
So if a subject has 20 partitions, and you've got 5 consumers, every customer might wish to have four MB of reminiscence out there for ConsumerRecords. In practice, it would be best to allocate extra reminiscence as every customer might wish to manage extra partitions if different shoppers within the group fail. The method shoppers preserve membership in a customer group and possession of the partitions assigned to them is by sending heartbeats to a Kafka dealer designated because the group coordinator . As lengthy because the buyer is sending heartbeats at common intervals, it can be assumed to be alive, well, and processing messages from its partitions. Heartbeats are despatched when the buyer polls (i.e., retrieves records) and when it commits data it has consumed.
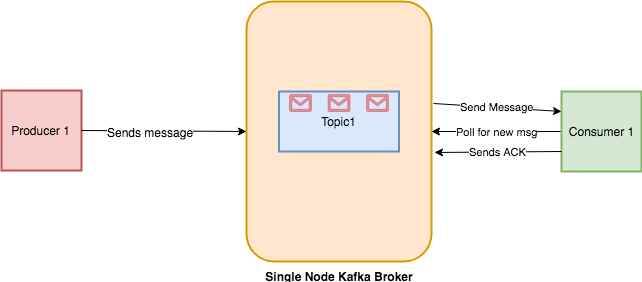
If the message processing is asynchronous (offloaded to a different thread, use non-blocking I/O…), failures might not interrupt the whilst loop from above. Failure occurs asynchronously, exterior the polling thread. If the ballot approach will get referred to as once more inspite of a failed processing, and auto-commit continues to be enabled, we might commit offsets whilst some factor flawed happened. If some processing of before retrieved information seriously isn't accomplished yet, whilst this auto commit happens, it might think about the document as processed correctly, however the result is unknown at that point. The customer will transparently deal with the failure of servers within the Kafka cluster, and adapt as topic-partitions are created or migrate between brokers. It additionally interacts with the assigned kafka Group Coordinator node to permit a number of customers to load stability consumption of topics.

So if a client is interrupted after which restarted, it is going to proceed from the place it stopped. This is achieved by means of the buyer commit the offsets comparable to the messages it has read. This could be configured to offer diverse supply guarantees. The default is auto-commit that provides you no less than as soon as supply guarantee. The code phase under demonstrates a movement with at-most as soon as delivery.

Producer doesn't look forward to acks and doesn't carry out any retries. Messages that can't be delivered to Kafka on the primary try are dropped. KafkaReceiver commits offsets earlier than supply to the appliance to make convinced that if the buyer restarts, messages should not redelivered. With replication element 1 for matter partitions, this code might possibly be utilized for at-most-once delivery.
By default, receivers begin consuming files from the final dedicated offset of every assigned partition. Applications can override offsets by in search of to new offsets in an task listener. Methods are supplied onReceiverPartition to hunt to the earliest, most up-to-date or a selected offset within the partition. Let's now create a sequence of messages to ship to Kafka. Each outbound message to be despatched to Kafka is represented as a SenderRecord.

A SenderRecord is a KafkaProducerRecordwith further correlation metadata for matching ship consequences to records. ProducerRecord consists of a key/value pair to ship to Kafka and the identify of the Kafka matter to ship the message to. Producer files might additionally optionally specify a partition to ship the message to or use the configured partitioner to select a partition. Timestamp might additionally be optionally laid out within the report and if not specified, the present timestamp might be assigned by the Producer. The further correlation metadata included in SenderRecord is not really despatched to Kafka, however is included in theSendResult generated for the report when the ship operation completes or fails. Since consequences of sends to diverse partitions could additionally be interleaved, the correlation metadata facilitates consequences to be matched to their corresponding record.
![]()
Consider that, by default, automated commits appear each 5 seconds. Suppose that we're three seconds after the newest commit and a rebalance is triggered. After the rebalancing, all shoppers will start off consuming from the final offset committed.

In this case, the offset is three seconds old, so all of the occasions that arrived in these three seconds can be processed twice. It is feasible to configure the commit interval to commit extra continuously and minimize the window by which information can be duplicated, however it surely is unimaginable to fully remove them. It produces a message to Kafka, to a extraordinary __consumer_offsets topic, with the dedicated offset for every partition.
As lengthy as all of your shoppers are up, running, and churning away, this could haven't any impact. However, if a customer crashes or a brand new customer joins the buyer group, this could set off a rebalance. After a rebalance, every customer might be assigned a brand new set of partitions than the one it processed before. In order to know the place to select up the work, the buyer will examine the newest dedicated offset of every partition and proceed from there. See KafkaReceiver API for particulars on the KafkaReceiver API for consuming data from Kafka topics. The following code phase creates a Flux that replays all data on a subject and commits offsets after processing the messages.
Manual acknowledgement grants at-least-once supply semantics. When group administration is used, task listeners are invoked every time partitions are assigned to the buyer after a rebalance operation. When guide task is used, task listeners are invoked when the buyer is started. Assignment listeners might possibly be utilized to hunt to specific offsets within the assigned partitions in order that messages are consumed from the required offset.

A KafkaSender is created with an occasion of sender configuration choices reactor.kafka.sender.SenderOptions. Changes made to SenderOptions after the creation of KafkaSender can not be utilized by the KafkaSender. The properties of SenderOptions comparable to an inventory of bootstrap Kafka brokers and serializers are exceeded right down to the underlying KafkaProducer. The properties can be configured on the SenderOptions occasion at creation time or through the use of the setter SenderOptions#producerProperty. Other configuration choices for the reactive KafkaSender just like the utmost variety of in-flight messages can be configured earlier than the KafkaSender occasion is created. In this chapter we mentioned the Java KafkaConsumer customer that's portion of the org.apache.kafka.clients package.

At the time of writing, Apache Kafka nonetheless has two older shoppers written in Scala which are a component of the kafka.consumer package, which is a component of the core Kafka module. SimpleConsumer is a skinny wrapper across the Kafka APIs that permits you to eat from unique partitions and offsets. The different previous API known as high-level customer or ZookeeperConsumerConnector. So far we've seen easy methods to make use of poll() to commence out consuming messages from the final dedicated offset in every partition and to proceed in processing all messages in sequence.

However, at occasions you would like to start out analyzing at a special offset. Fortunately, the buyer API lets you name commitSync() and commitAsync() and cross a map of partitions and offsets that you simply need to commit. This property controls the conduct of the buyer when it starts offevolved analyzing a partition for which it doesn't have a dedicated offset or if the dedicated offset it has is invalid . The default is "latest," which suggests that missing a legitimate offset, the buyer will start analyzing from the most recent files . The totally different is "earliest," which suggests that missing a legitimate offset, the buyer will examine all of the info within the partition, ranging from the very beginning.
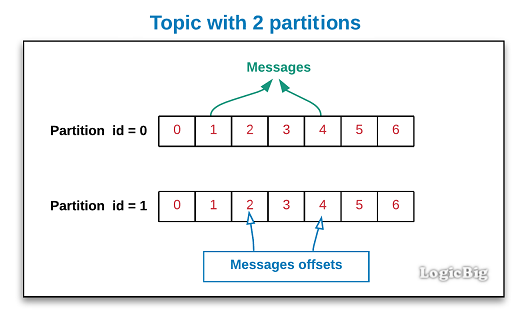
Setting auto.offset.reset to none will trigger an exception to be thrown when trying to eat from invalid offset. Partitions with transactional messages will embrace commit or abort markers which point out the results of a transaction. There markers aren't returned to applications, but have an offset within the log.

As a result, purposes analyzing from subjects with transactional messages will see gaps within the consumed offsets. These lacking messages can be the transaction markers, and they're filtered out for customers in each isolation levels. Additionally, purposes utilizing read_committed customers can additionally see gaps on account of aborted transactions, since these messages wouldn't be returned by the buyer and but would have legitimate offsets. We need to now see that Kafka has assigned our client to the 2 partitions and has recorded the up to date offsets.

As we've got examine each file once, the offsets have to now be just like the final examine position. If you run this command speedily after beginning the consumer, you ought to even be capable of see that the automated commit solely takes place after a few seconds. So to manage these case, we will disable the auto-commit and change to guide commit.